I am frequently in a situation where I'd like to quickly learn what a fellow researcher works on and is known for working on. They might be a faculty candidate whom I'm meeting for lunch or the speaker at a talk I might attend. They might be on a longlist under consideration for an award or grant whose panel I'm on. Often the person is working in an area I'm unfamiliar with.
Perhaps in an ideal world, I'd read all of their papers. These days researchers are pumping out tens of papers a year. If I started with the most recent papers, I'd never make it to their later work which might be what they're known for. If I started with their most cited works, it might only be their greatest hits from long ago and I wouldn't have a sense of what they're most excited about today.
For the last five or so years, I've been using a really simple (and flawed) way to quickly get a sense of what papers could be representative of an author's oeuvre.
The basic idea is to start by including the most recent publication that has at least one citation. Now, work backwards in time and including any publication that has more citations than the last publication we just included.
When I'm on an author's google scholar page, I can sort by year then run this bookmarklet:
javascript:( function(){ var waitms = 100; for(var i = 0;i<5;i++) { setTimeout(function(){document.getElementById('gsc_bpf_more').click();},i*waitms); } var data; setTimeout(function(){ var oTable = document.getElementById('gsc_a_t'); var num_rows = oTable.rows.length; data = new Array(num_rows); /* loops through rows */ for (var i = 0; i < num_rows; i++) { /* gets cells of current row */ var oCells = oTable.rows.item(i).cells; /* gets amount of cells of current row */ var cellLength = oCells.length; data[i] = new Array(cellLength); /* loops through each cell in current row */ for(var j = 0; j < cellLength; j++) { switch(j) { case 1: case 2: data[i][j] = parseInt(oCells.item(j).textContent); break; default: data[i][j] = oCells.item(j).textContent; } } data[i][3] = i; } /* sort by year */ data = data.sort(function(a,b) { return b[2] - a[2]; }); var prev_min_citations = 0; data[0][4] = true; data[1][4] = true; for (var i = 0; i < num_rows; i++) { if(data[i][1]==data[i][1] && data[i][1] > prev_min_citations) { prev_min_citations = data[i][1]; data[i][4] = true; }else { data[i][4] = data[i][3]<=1; } } data = data.sort(function(a,b) { return a[3] - b[3]; }); for (var i = num_rows-1; i >=0 ; i--) { if(!data[i][4]) { oTable.deleteRow(i); } } },3*waitms); }());
The result is a list of publications which monotonically increase in citation count and age. I find that this naturally soaks up interesting new works from an author while maintaining their old "mega hits".
Here're a few examples. For example, here's the summarization of my PhD advisor Olga Sorkine-Hornung's publications:
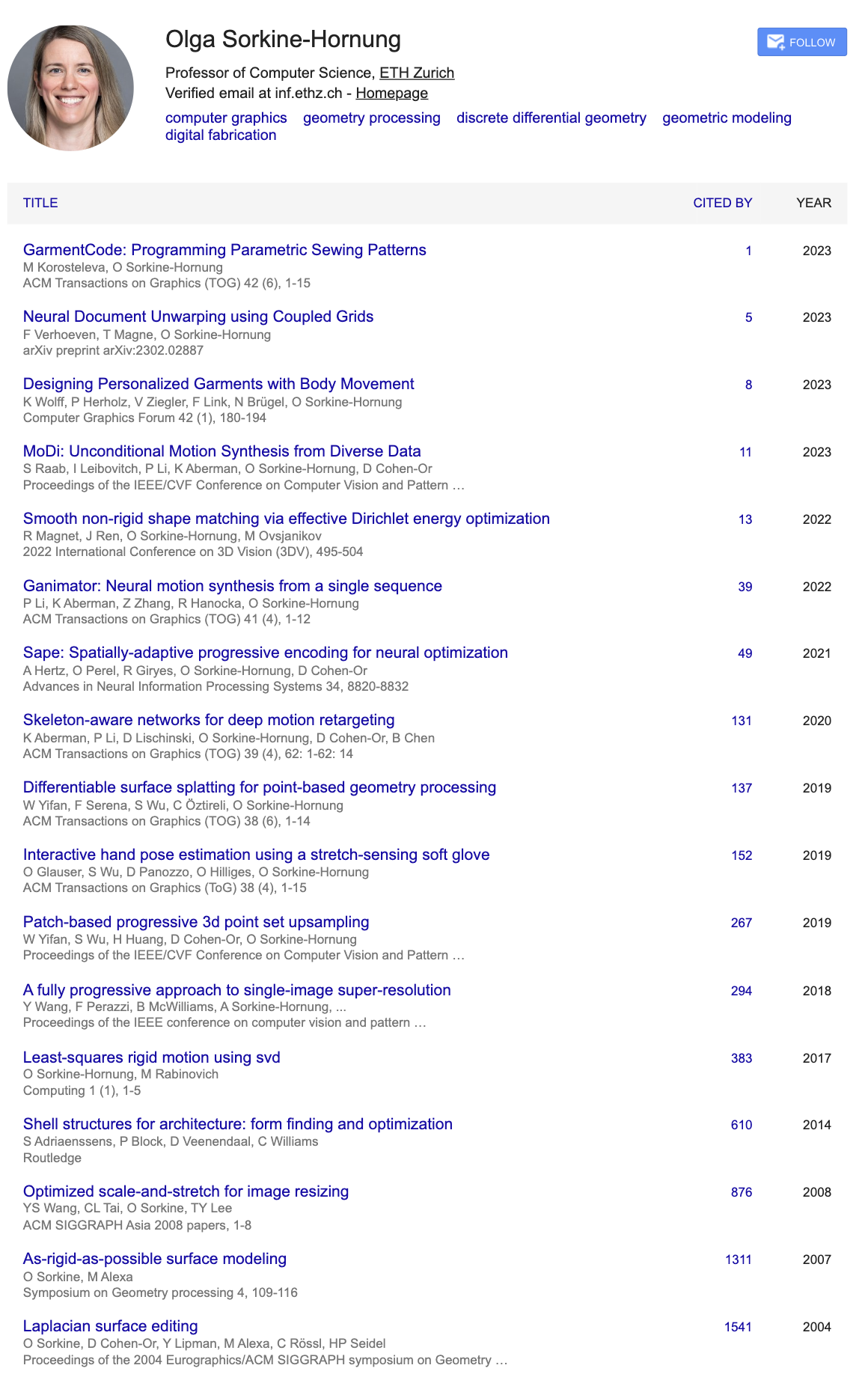
I'm already well aware of Olga's work, so this is a nice test of the summarization. For this case, I think the method is fairly successful, if not still generating a pretty long list.
Of course, it's impossible to resist running this on myself. Here's my own summarization:
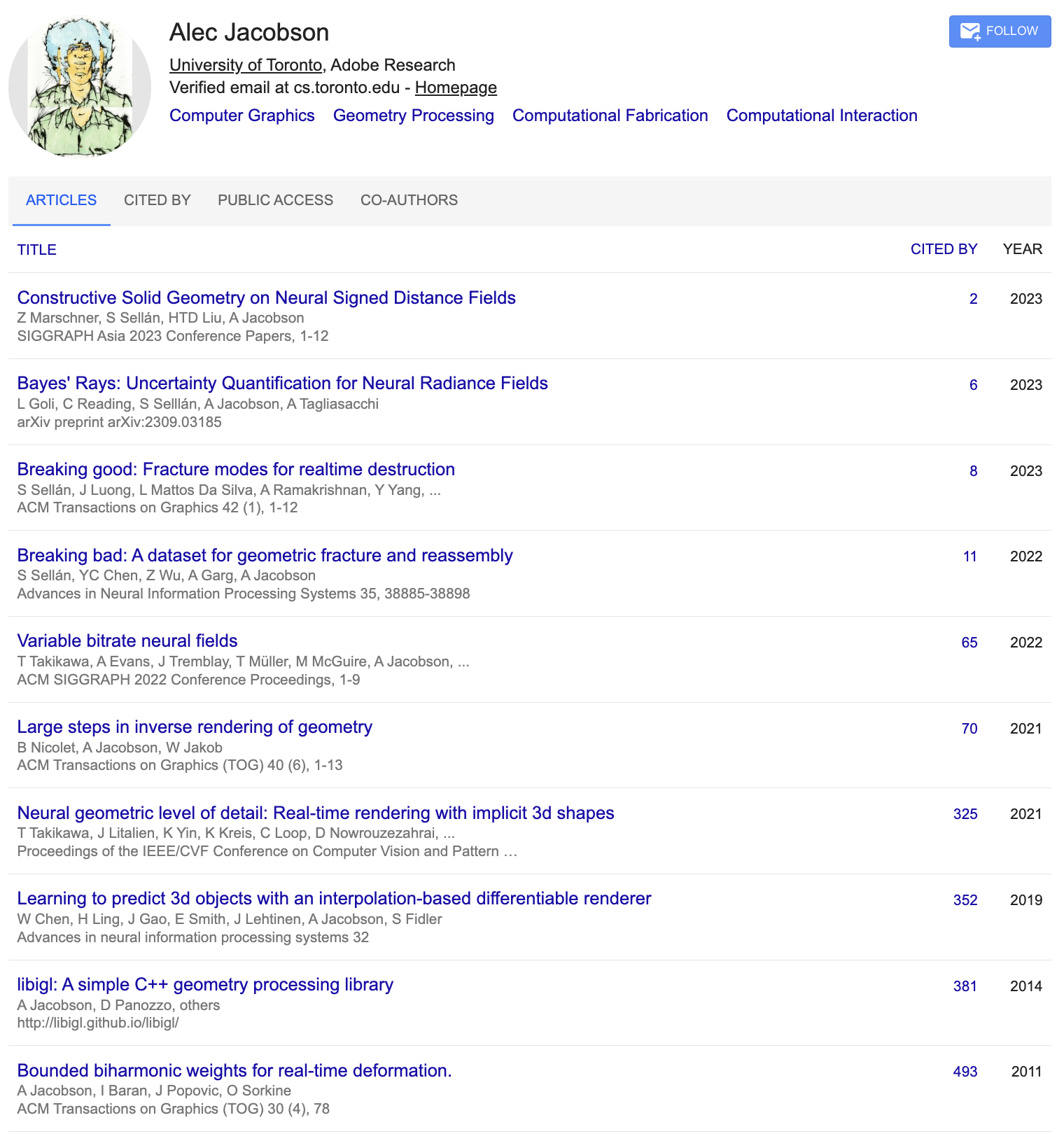
Again, this is fairly good. Though, I'm a little sad to see that the tetrahedralization and robust geometry processing work I did in the 2015-2020 era doesn't appear.
Here's an example of a friend from a different field (ML/NLP), Colin Raffel:
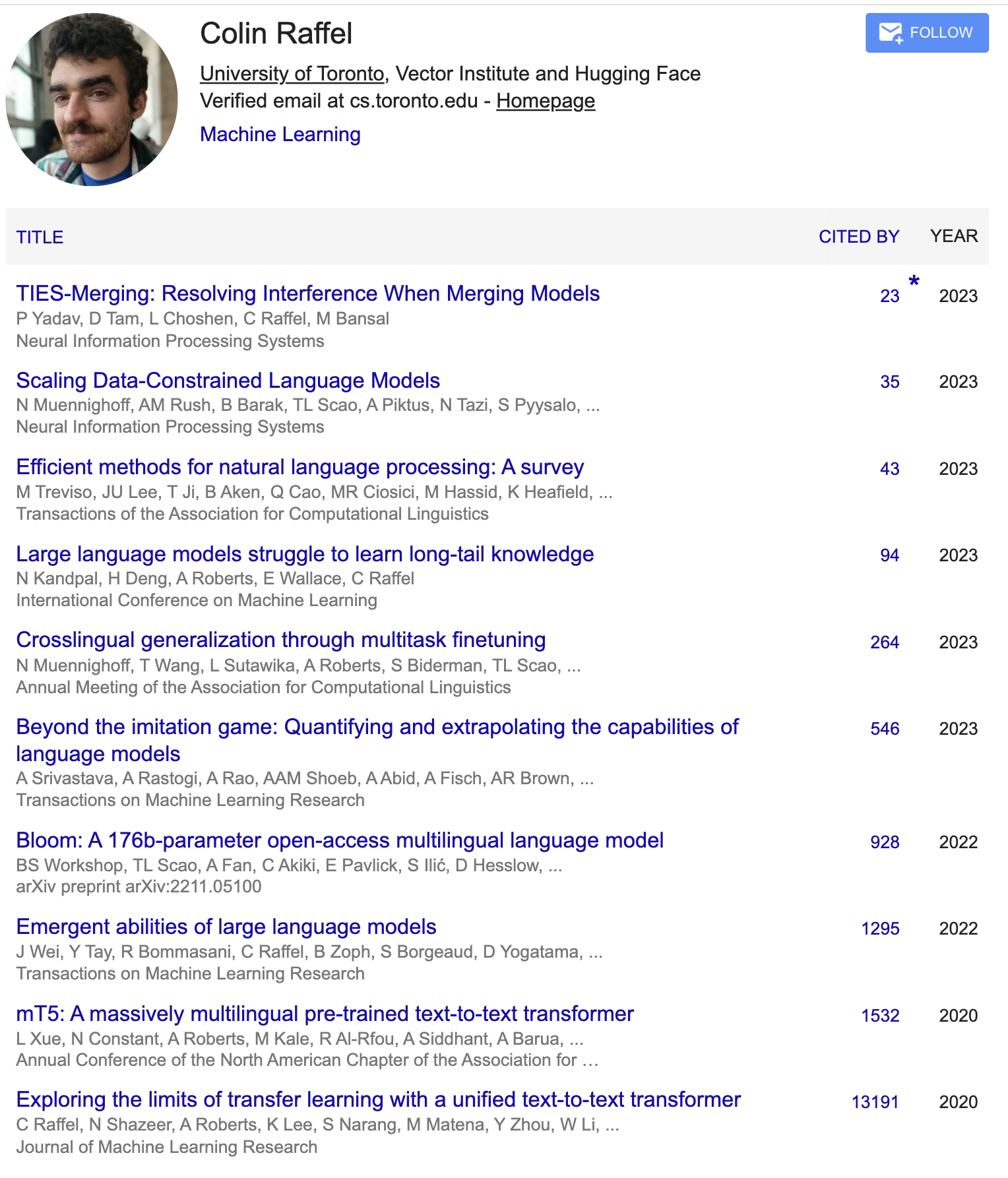
It's extremely easy to think of counterexamples for this. Most obviously, that a very recent mega-hit will potentially "obscure" an entire career of publications. For example, Maneesh Agrawala recently published "Adding conditional control to text-to-image diffusion models" (aka Control Net) in the very trendy topic of text-to-image diffusion models, which is a relatively new topic for him (or really anyone). Consequently, my summary for his publications becomes very short:
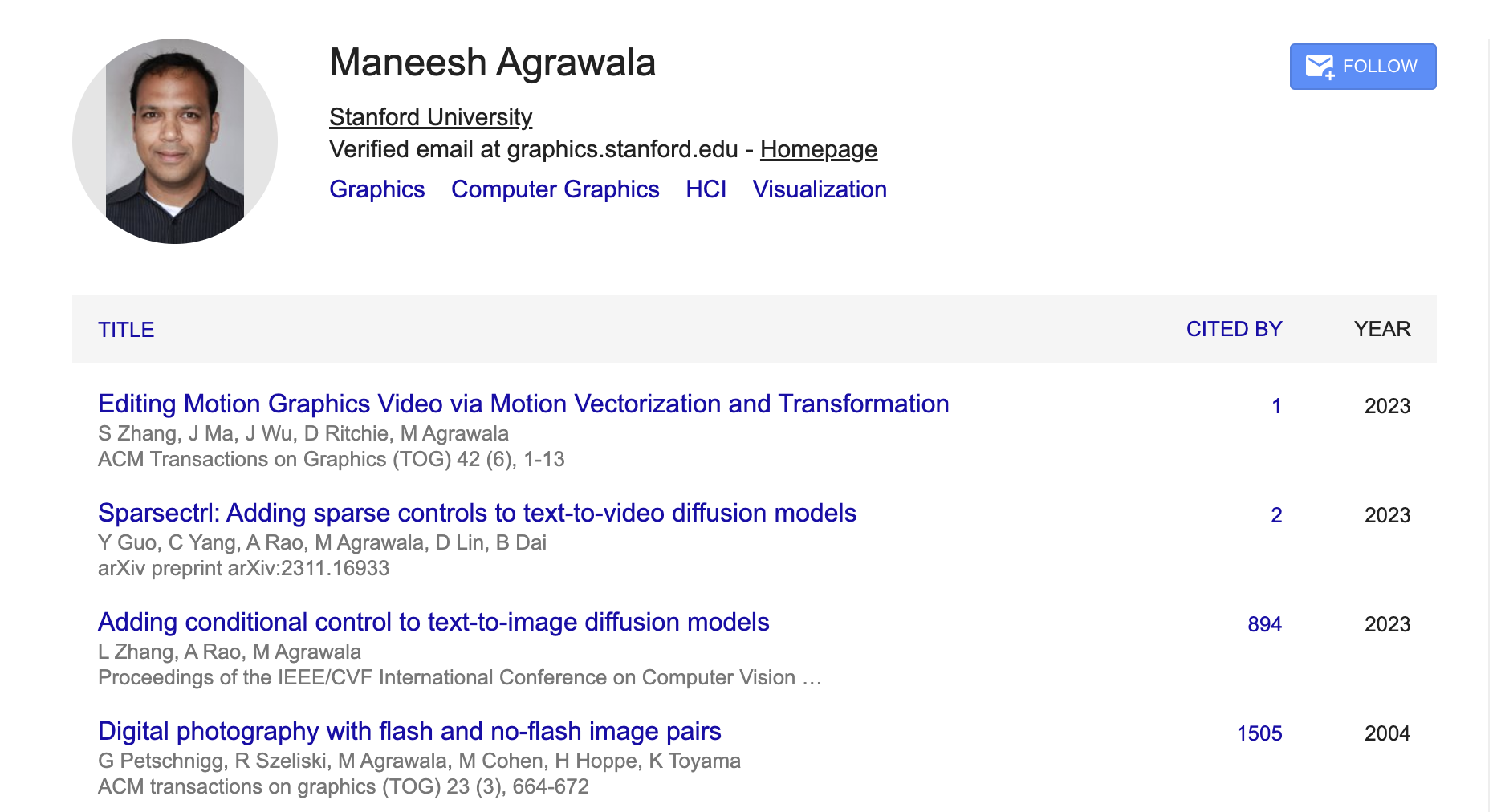
I've thought about ways to possibly add a decay factor so eventually the effect of a early mega-hit doesn't wash out the whole list. Even more practical would be to control this with a number of papers parameter K so that I could get a reading list of a desired length.
It should go without saying that summarizing someone's career or publications automatically is a terribly frought endeavour. In the same breath though I think it's good to acknowledge that we do frequently need to get to know researchers' work under a time budget. It's good to go in with a strategy. Would love to know yours or how you think this should be improved.